
Mit dem Pixel Feature Drop für Dezember 2022 hat der Google Recorder ein Update mit Erkennung der Sprecher erhalten. Google erklärt nun in einem Blog-Eintrag, wie die Speaker-Labels funktionieren.
Google Recorder – Speaker Labels mit Unterstützung von Turn-to-Diarize
Mit dem Pixel Feature Drop für Dezember 2022 hat Google die Speaker Labels auf Google Recorder Version 4.2 verfügbar gemacht. Diese sind standardmäßig deaktiviert und können ab sofort über die Rekorder-Einstellungen auf dem Pixel 6, 6 Pro, 6a, 7 und 7 Pro -> Sprecher-Labels aktiviert werden. Bisher sind die Speaker Labels nur auf Englisch (englischer Text, englische Transkripte) verfügbar. Die Transkriptsprache Englisch stellst du ebenfalls über die Rekorder-Einstellungen -> Sprache des Transkriptes ein.




Sofern nun mehrere Personen einen Dialog auf Englisch führen, erkennt die Rekorder-App die einzelnen Personen automatisch und kennzeichnet sie als Speaker/Sprecher 1, Speaker 2 usw.

Im Transkript kannst du die Sprecherlabels auch bearbeiten, indem du auf den Button mit den drei Linien und dem Stift klickst.

Speaker Labels werden von Googles neuem Sprecher-Diarisierungssystem namens Turn-to-Diarize unterstützt, das erstmals auf der ICASSP 2022 vorgestellt wurde
Systemarchitektur
Das Sprecher-Diarisierungssystem nutzt mehrere hochoptimierte Modelle und Algorithmen für maschinelles Lernen, um mit begrenzten Rechenressourcen auf mobilen Geräten stundenlanges Audio-Diarisieren in Echtzeit-Streaming zu ermöglichen.
- Das System besteht im Wesentlichen aus drei Komponenten:
- einem Sprechererkennungsmodell, das einen Wechsel des Sprechers in der Eingabesprache erkennt
- einem Sprechercodierermodell, das Stimmeigenschaften aus jedem Sprecherwechsel extrahiert
- einem mehrstufigen Clustering-Algorithmus, der auf hocheffiziente Weise Lautsprecherbeschriftungen kommentiert.
Alle Komponenten laufen vollständig auf dem Gerät.
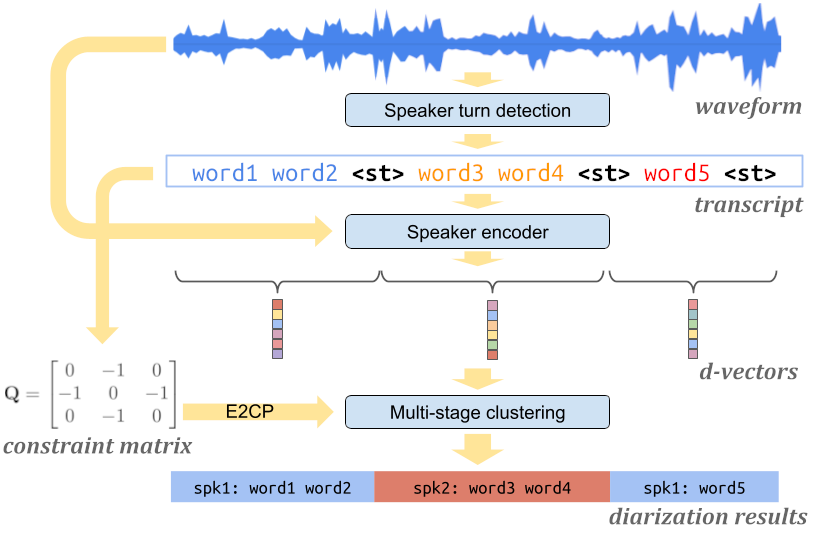
So verarbeitet die Rekorder App die Daten für Sprecherlabels
Wenn Sie Sprecherlabels aktivieren, analysiert die Recorder App Ihre Audioaufnahmen, erkennt dabei bestimmte Sprecher in Ihren Transkripten und fügt ihnen Labels hinzu. So funktionierts:
- In den Aufnahmen auf Ihrem Gerät werden Modelle der Stimmen erstellt
- Jede erkannte Stimme wird mit einem generischen Textlabel versehen (z. B. „Speaker 1“ oder „Speaker 2“)
- Die Stimmen werden innerhalb der Aufnahme verglichen, damit im Transkript korrekt wider gegeben werden kann, welcher Sprecher was wann gesagt hat.
Die oben beschriebenen Schritte werden auf Ihrem Smartphone ausgeführt und die generierten Sprechertextlabels werden dann in Ihrem Transkript gespeichert. Hinweis: Die oben genannten Sprachmodelle können in einigen Ländern oder Regionen als biometrische Daten betrachtet werden.
Richtlinie zum Aufbewahren und Löschen von Sprachmodellen
Die zur Erstellung von Sprecherlabels verwendeten Sprachmodelle werden vorübergehend auf dem Gerät gespeichert, bis das Transkript mit Sprecherlabels versehen ist. Anschließend werden sie gelöscht (normalerweise innerhalb weniger Minuten).